
【Informatica CDGC】ノーコードとSQLのマッピングを比較して、データリネージュに違いがあるのか検証してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんにちは、データ事業本部の渡部です。
今回はInformaticaのCloud Data Governance and Catalog(以降、CDGC)でノーコード(標準マッピング)とSQLを使用したマッピングで、リネージュの出力に違いがあるのかを調べてみます。
InformaticaのETLサービス、Cloud Data Integration(以降、CDI)はノーコードでトランスフォーメーションと呼ばれる部品を駆使してETLを作成することができます。
データフローが一目で見やすい一方で、複雑なデータ加工になってくると、Informaticaがノーコードから作成したSQLがお化けSQL(何千行のSQL)になってしまう場合 があります。こうなってしまうと、処理が長期化する弊害が出てきます。
このようなケースをはじめ、SQLを使って処理を書いてしまいたい場合があるのですが、その際CDGCのでのリネージュがどのように出力されるかが気になりました。
重要なメタデータが出力されないなどがなければ、SQLで処理記述するのは1つの選択肢として採用できます。
今回の調査でそこを明らかにしていきます。
結論!
普段通りのマッピングとSQLを使用したマッピングで、データリネージュに差異はありませんでした。
データ加工のロジックのメタデータ抽出で多少の差異がありましたが、SQLでETL開発をしても問題ないと言えそうです。
検証
前提
検証用に、Redshift DWHテーブルからRedshift DataMartテーブルへのETLを作成していきます。
普段のマッピングとSQLを使ったマッピングで使用するテーブルはわけたかったので、同じ定義のものを複製して使用します。
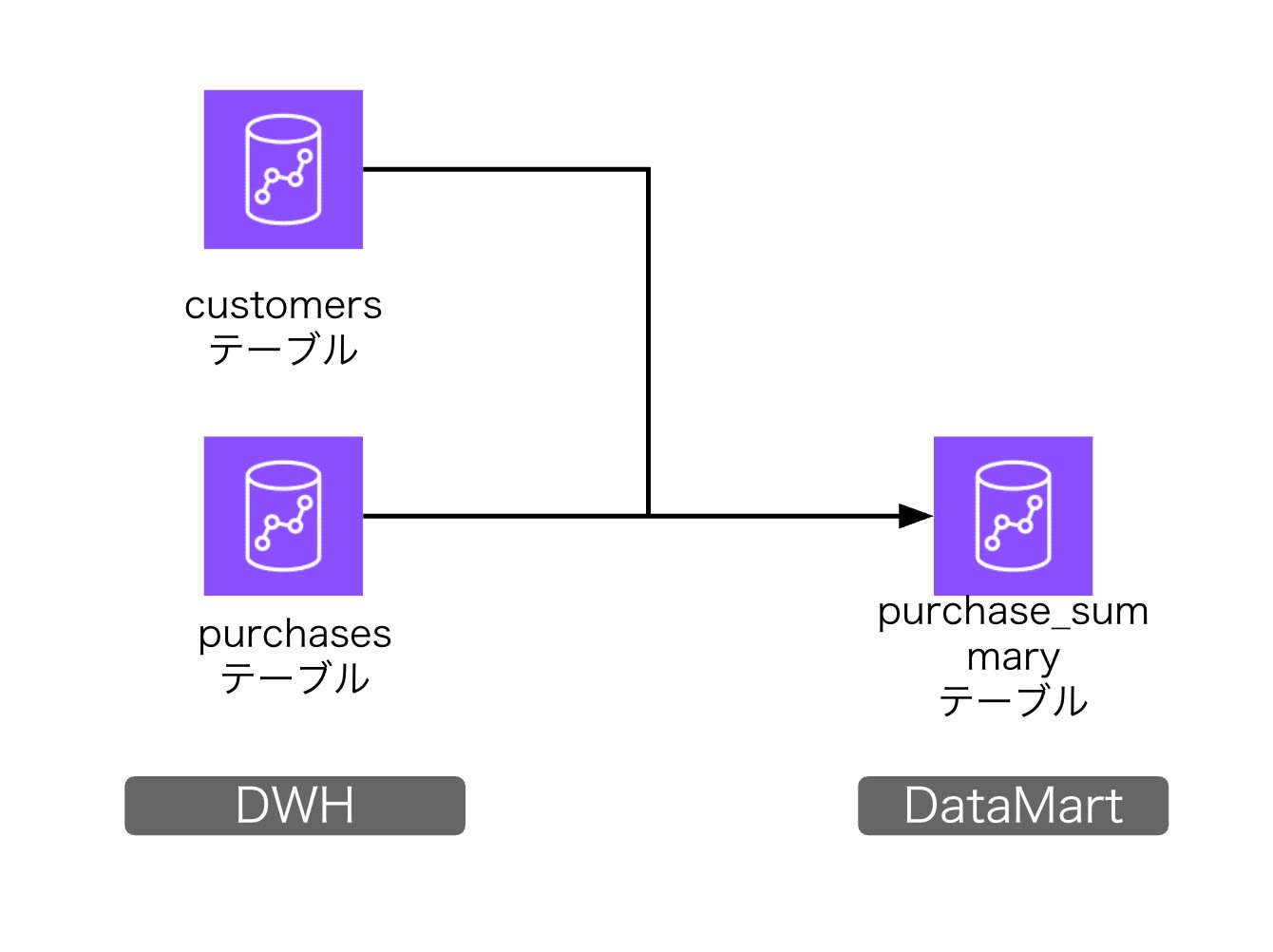
それぞれのテーブル定義は以下のとおりです。
-- ソーステーブル1: 顧客テーブル
CREATE TABLE dwh.customers (
customer_id INTEGER PRIMARY KEY,
customer_name VARCHAR(100),
age INTEGER,
created_at TIMESTAMP
);
-- ソーステーブル2: 購入テーブル
CREATE TABLE dwh.purchases (
purchase_id INTEGER PRIMARY KEY,
customer_id INTEGER,
amount DECIMAL(10,2),
created_at TIMESTAMP
);
-- ターゲットテーブル
CREATE TABLE dm.purchase_summary (
summary_id INTEGER PRIMARY KEY,
total_amount DECIMAL(10,2),
created_at TIMESTAMP
);
サンプルデータは以下のとおりとなります。
テーブル名:dwh.customers
| customer_id | customer_name | age | created_at |
|---|---|---|---|
| 1 | 山田太郎 | 25 | 2023-01-01 10:00:00 |
| 2 | 鈴木花子 | 35 | 2023-01-01 10:15:00 |
| 3 | 佐藤次郎 | 45 | 2023-01-01 10:30:00 |
| 4 | 田中明子 | 25 | 2023-01-01 10:45:00 |
テーブル名:dwh.purchases
| purchase_id | customer_id | amount | created_at |
|---|---|---|---|
| 1 | 1 | 1000 | 2023-01-01 11:00:00 |
| 2 | 2 | 2000 | 2023-01-01 11:15:00 |
| 3 | 3 | 3000 | 2023-01-01 11:30:00 |
| 4 | 1 | 1500 | 2023-01-01 11:45:00 |
ETL処理は以下のSQLの出力をデータマートテーブルにTruncateInsertするものです。
※タイムゾーン変換のためcreated_at項目に多少の加工を入れています。
SELECT
p.customer_id as customer_id
,SUM(p.amount) as total_amount
,TO_CHAR(dateadd(hour, 9, sysdate), 'YYYY-MM-DD HH24:MI:SS') as created_at
FROM
dwh.purchases p
LEFT OUTER JOIN dwh.customers c
ON c.customer_id = p.customer_id
GROUP BY
p.customer_id
;
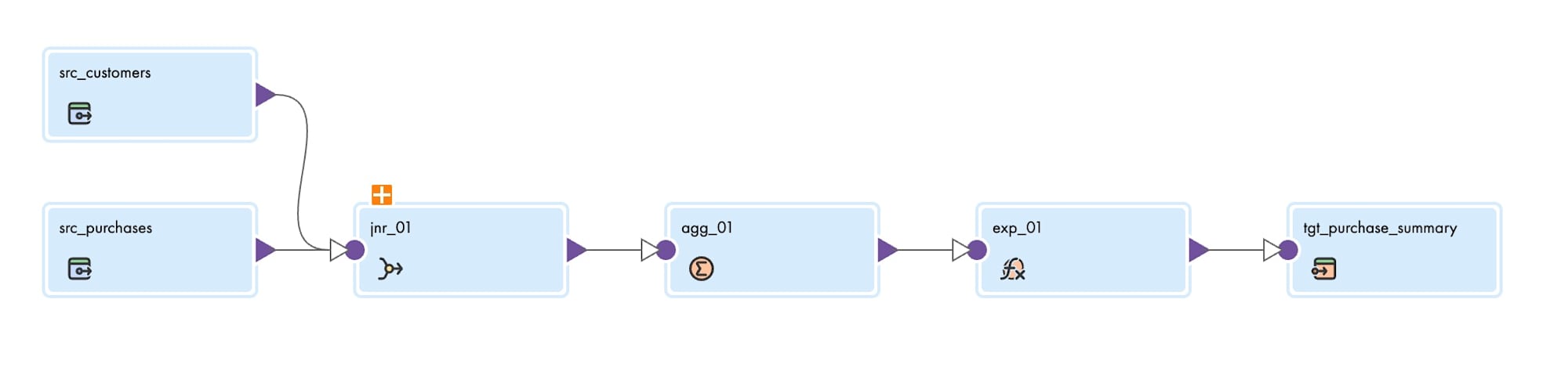
Informaticaのマッピングは普段どおりにノーコードで作成したものと、SQLで作成したものを用意しました。
普段どおりのマッピング
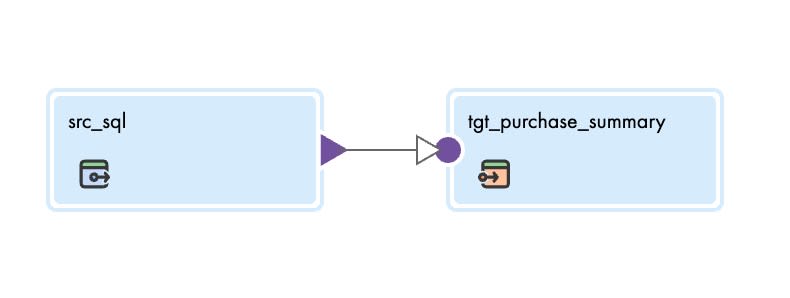
SQLで作成したマッピング
メタデータコマンドセンター
メタデータを抽出するため、まずはメタデータコマンドセンターを使用します。
今回はIDMC Metadataを使用してInformaticaのマッピングメタデータを取得します。
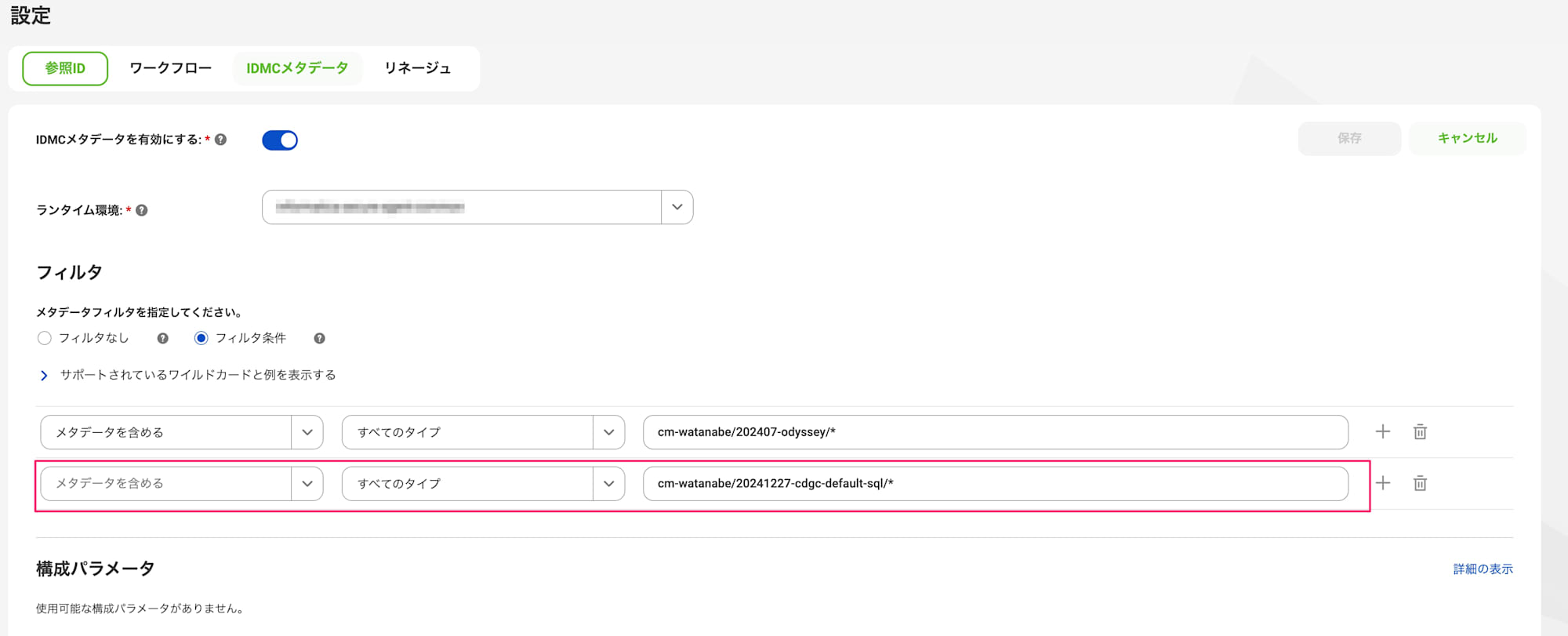
保存時のスキャンとマッピングタスク実行時のスキャンをして完了です。
詳しい設定は以下ブログをご参考ください。
つづいてRedshiftのメタデータを取得します。
dwhとdmスキーマの計6テーブルをスキャンしました。
詳しいメタデータ抽出設定は以下ブログをご参考ください。
CDGC
どのようにリネージュが表示されているか確認をします。
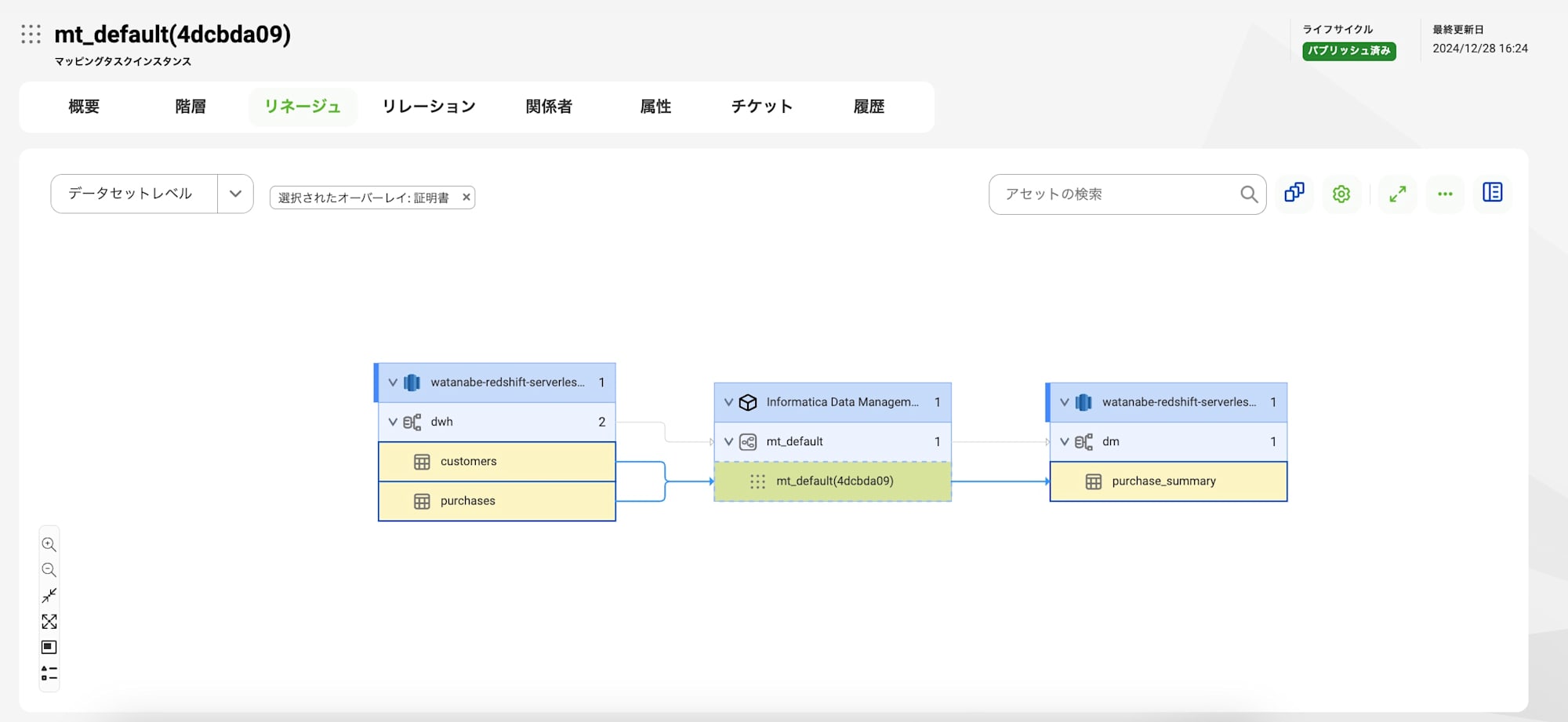
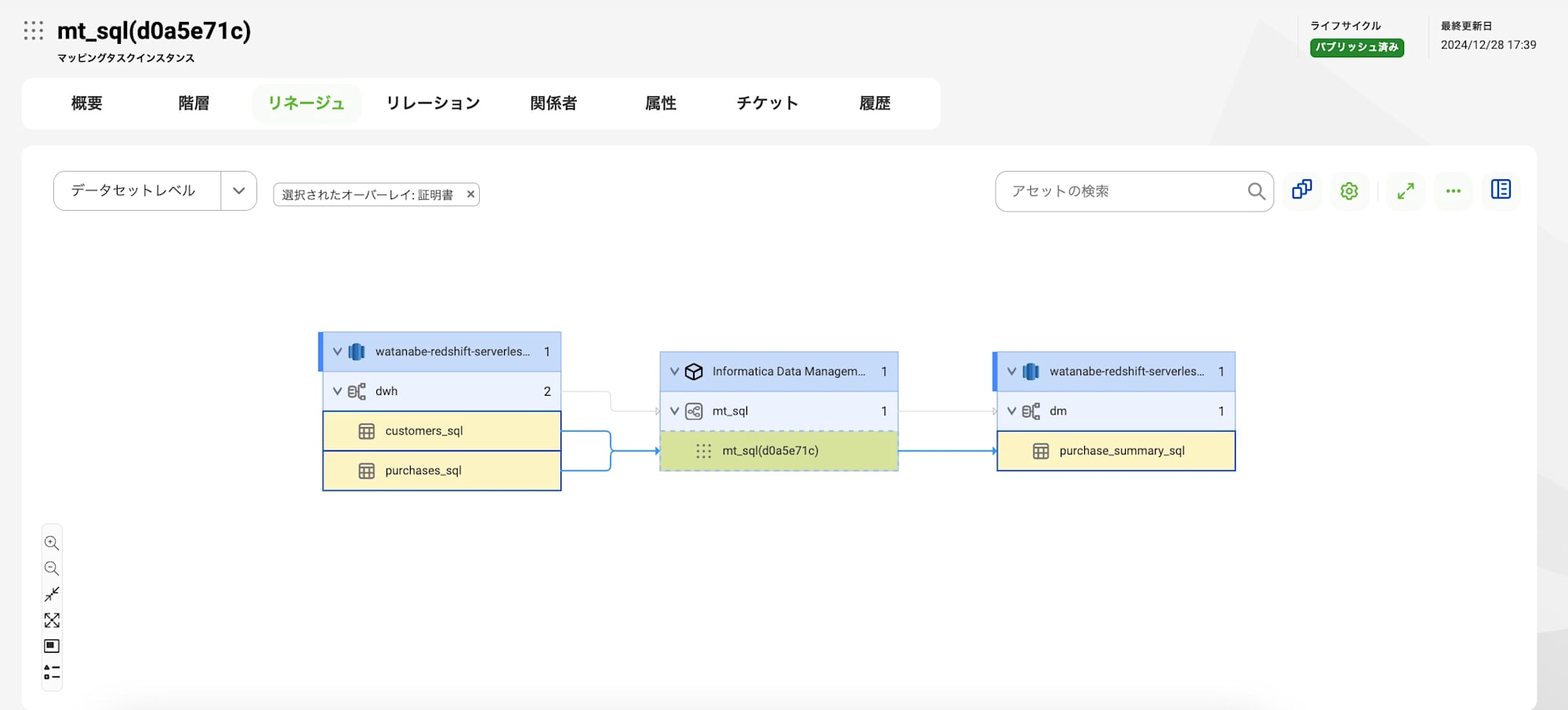
以下はデータセット(今回はテーブル単位)レベルでのリネージュです。
標準マッピング・SQLマッピングともに差異はなさそうです。
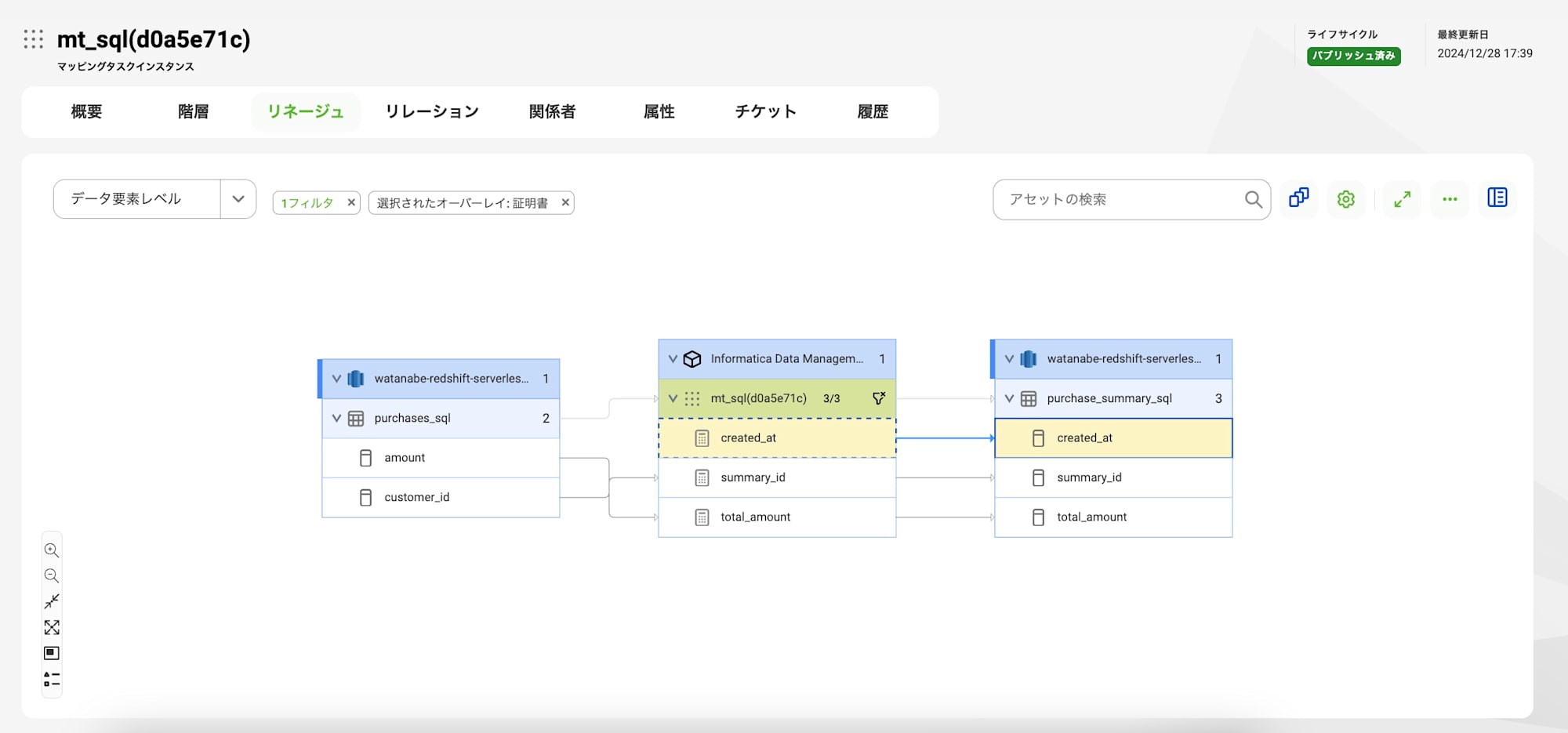
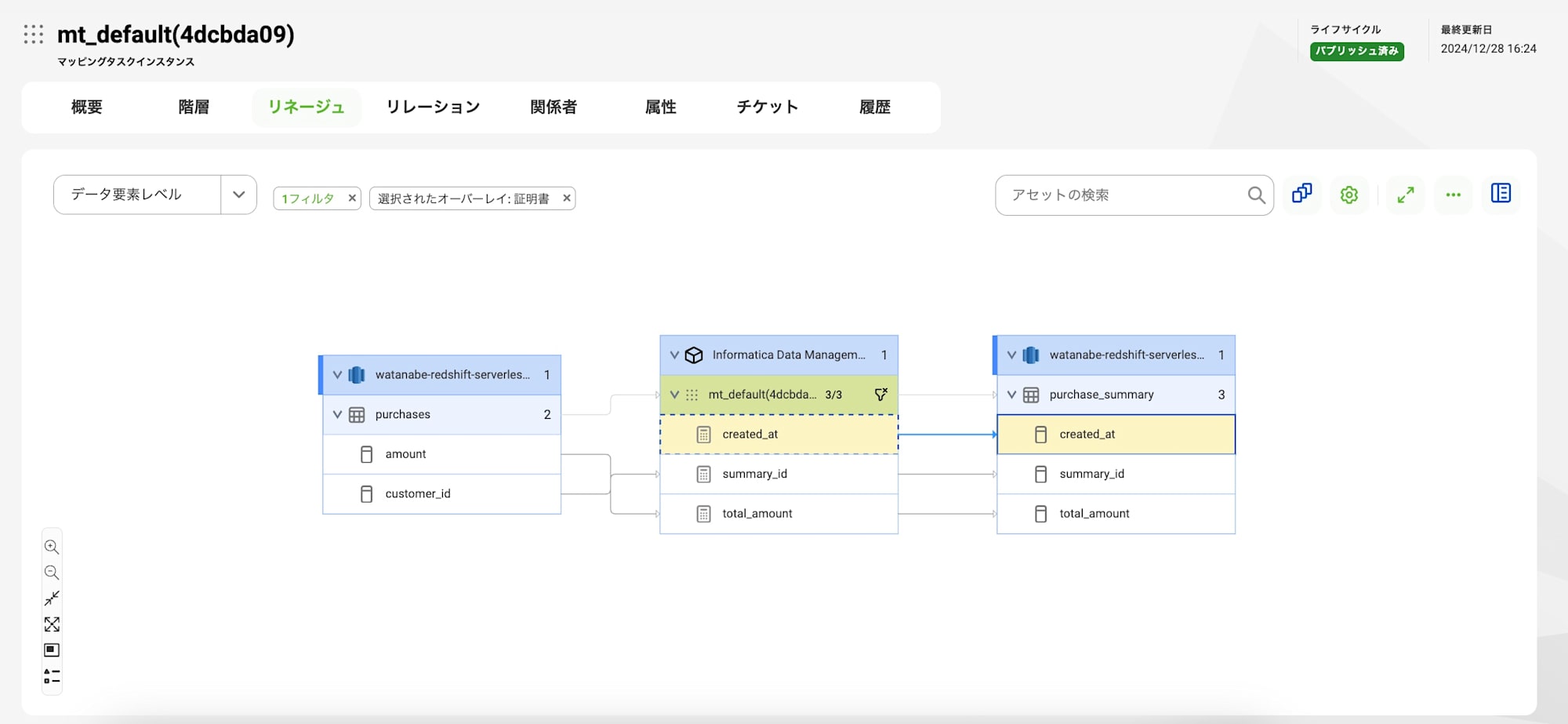
カラムレベルでも差異はなさそうです。
リネージュ上は差異がないように見えますね。
もしかして何も差異がないのでは・・・?と思いましたが、少しだけあったのでそちらをご紹介します。
データ加工ロジック情報が、標準の方が少し多く表示されていました。
今回のケースでいえば結合条件がそれにあたります。
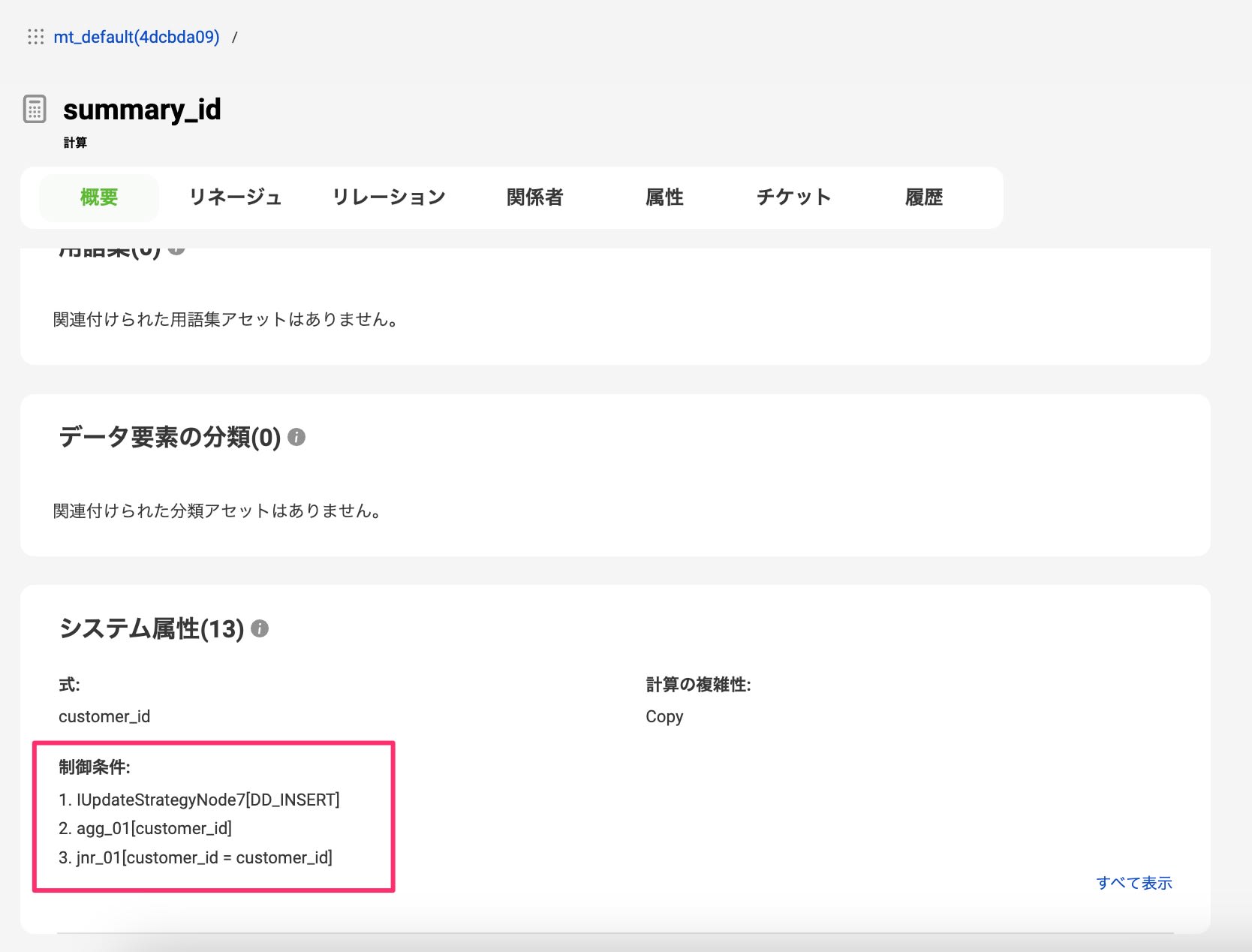
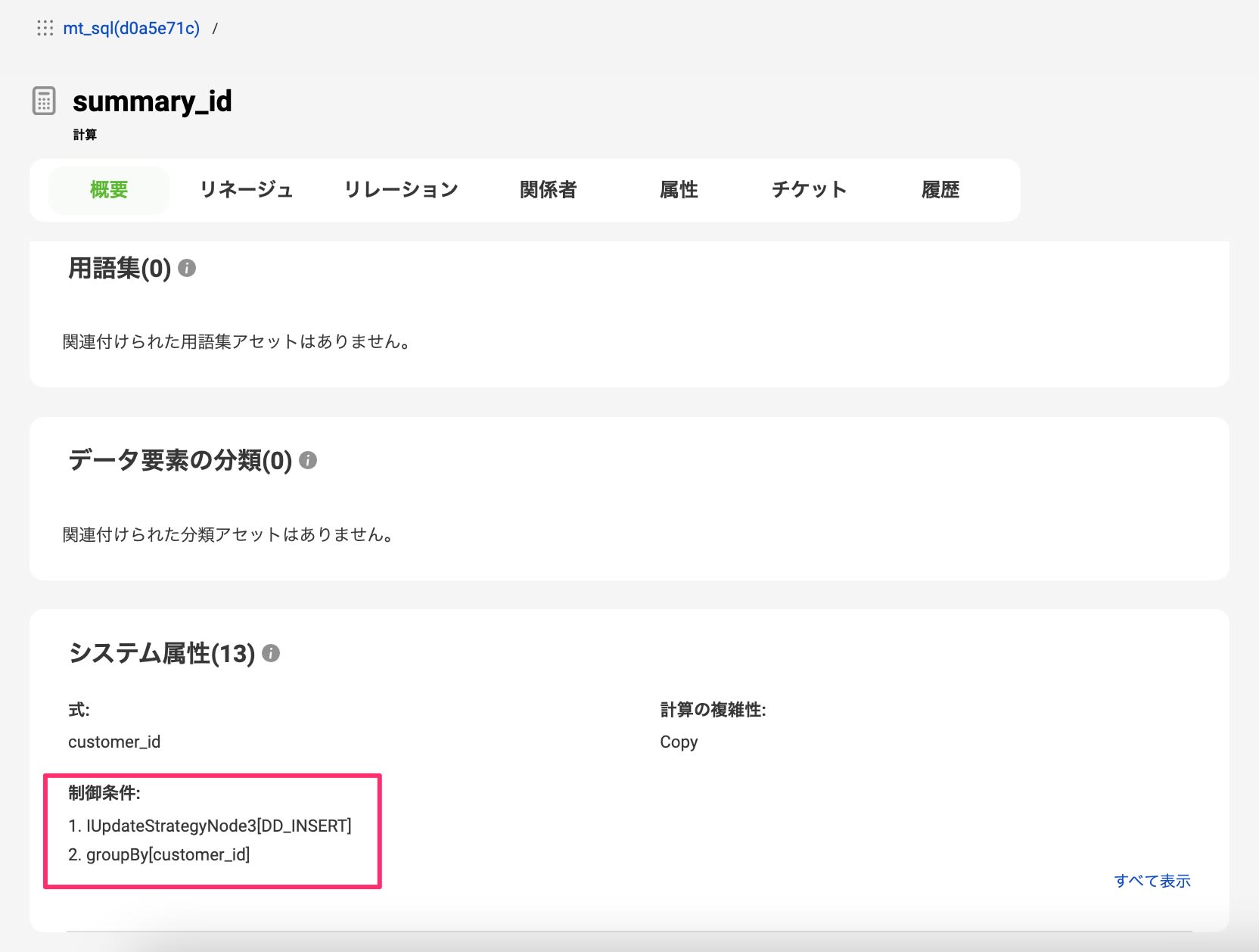
とはいえ、SQLの方はgroupByのロジックが取得できているのにも関わらず、joinが取れていないのはSQLの記法の問題もあるのかなと思い、少しSQLを変えてみました。
SQLのLEFT OUTER JOINの箇所をJOINに変更しました。
SELECT
p.customer_id as customer_id
,SUM(p.amount) as total_amount
,TO_CHAR(dateadd(hour, 9, sysdate), 'YYYY-MM-DD HH24:MI:SS') as created_at
FROM
dwh.purchases_sql p
JOIN dwh.customers_sql c
ON c.customer_id = p.customer_id
GROUP BY
p.customer_id
;
すると!先ほど表示されていなかった結合条件が表示されました。
単純にJOIN句の記載の問題のようです。
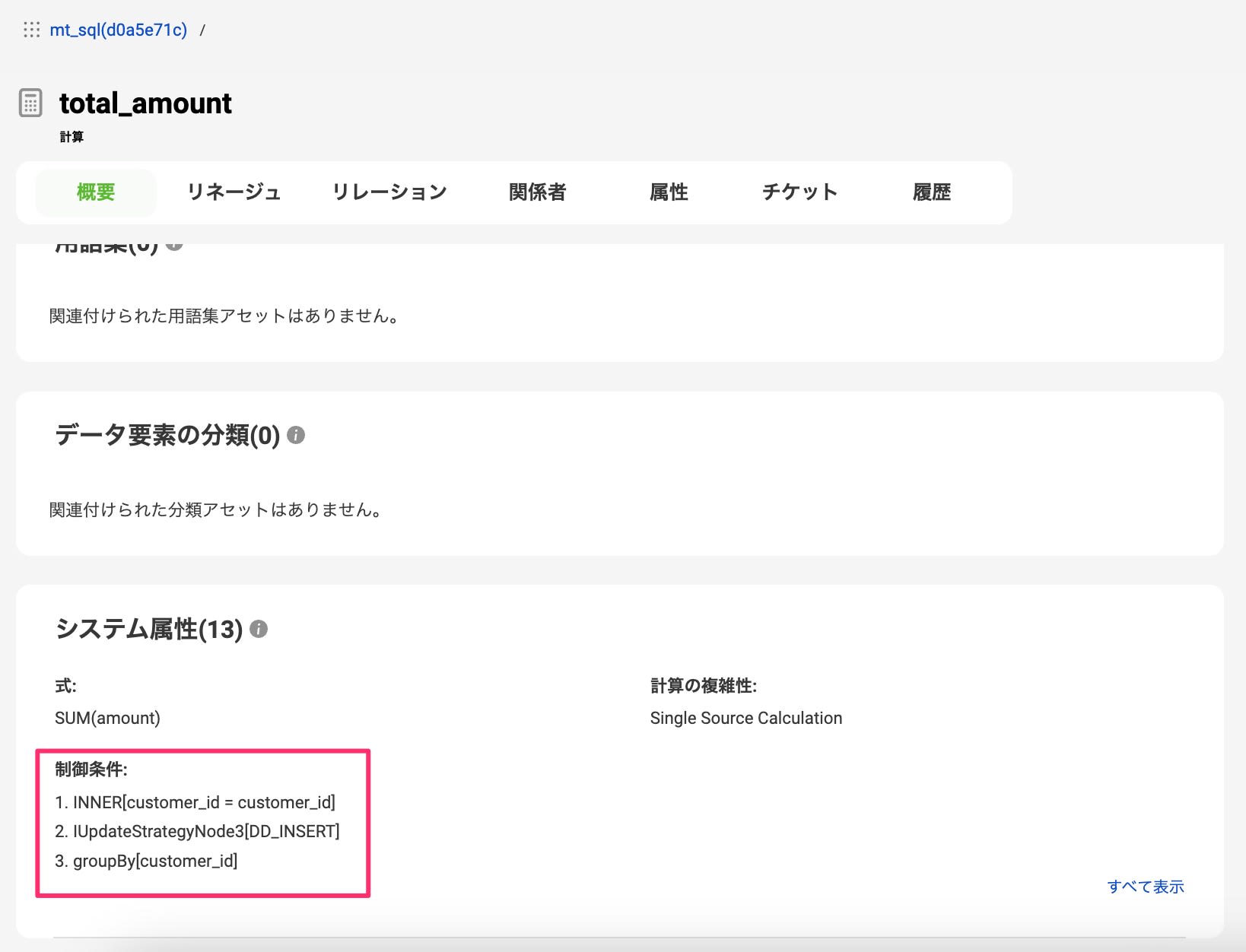
そのため今度はLEFT OUTER JOINの箇所をLEFT JOINに変更しました。
しかし・・・こちらは結合条件が表示されませんでした。
「なんでだろう」と思っていたらば、標準マッピングの方の結合条件を内部結合にしていることに気づきました。
もしかするとこれが原因で、実は外部結合の場合は標準マッピングでも結合条件が表示されないのかと思いました。
実際に結合条件をマスタ外部に変更してみて・・・
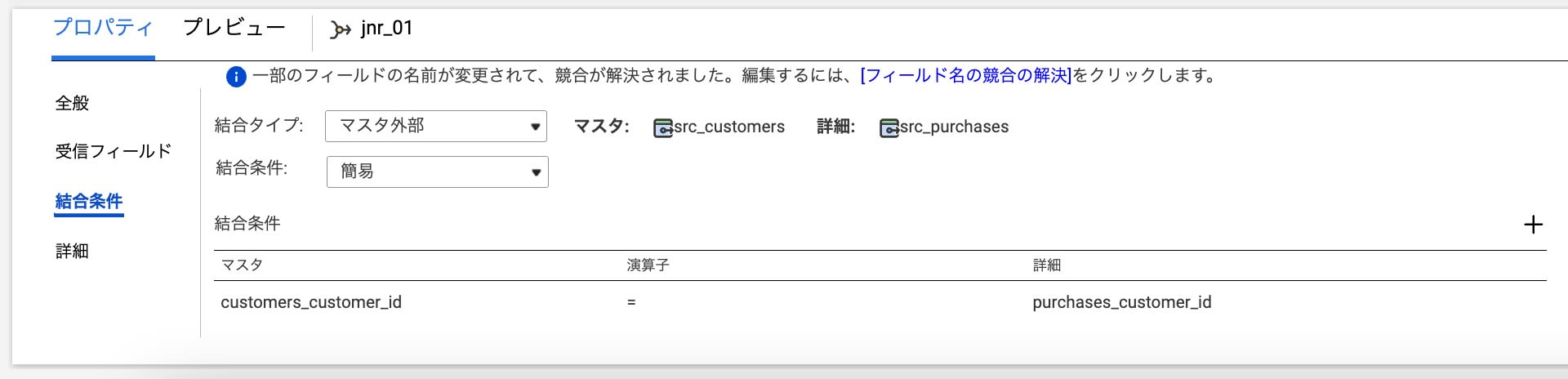
リネージュを確認、結果は・・・結合条件が表示されていました。
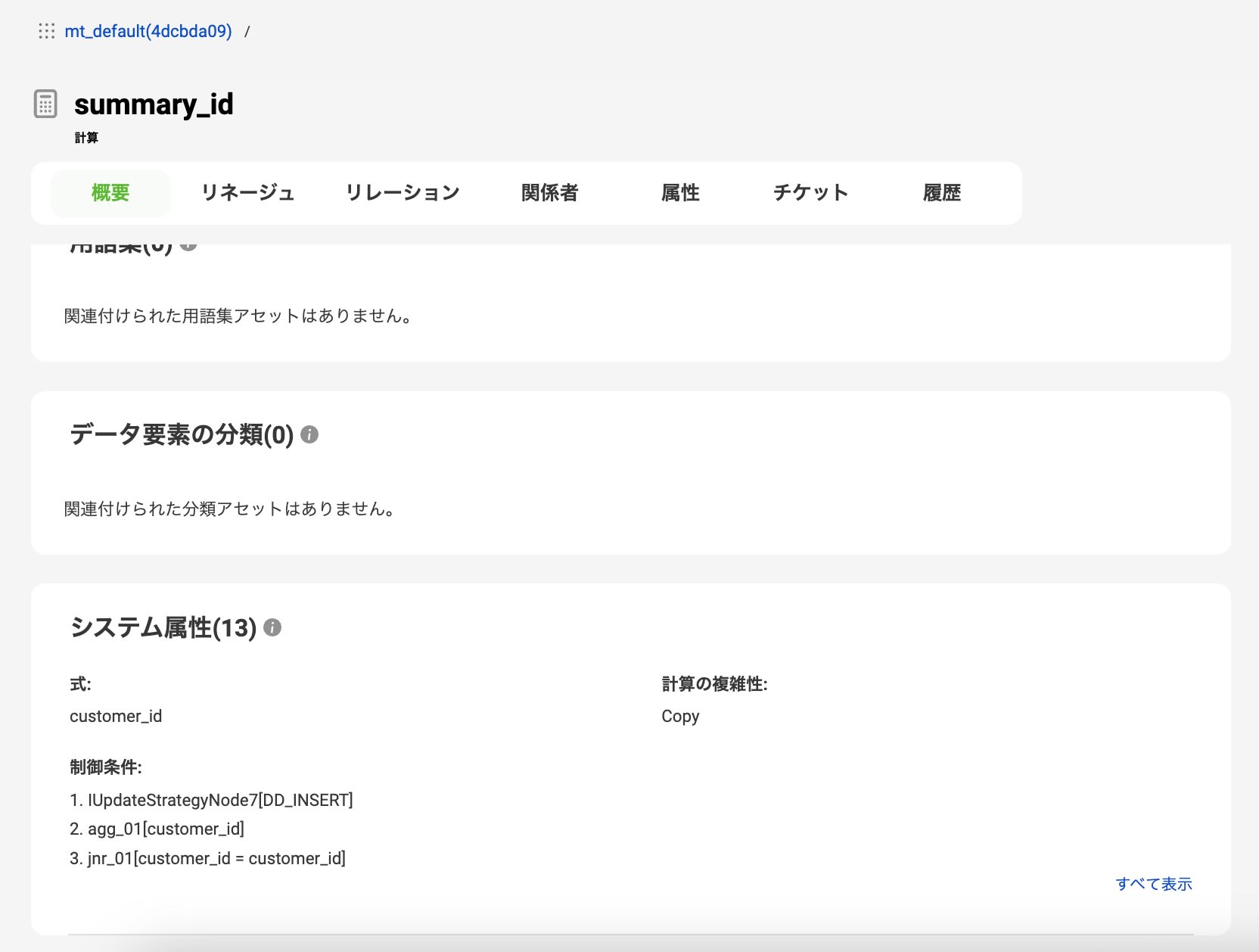
以上のことからSQLでの記載だと内部結合は対応しているが、外部結合は対応していないように見えます。
これは不思議な挙動なので、解決方法がありそうな気はしますね。
まとめ
標準マッピングとSQLマッピングではデータリネージュの出力に差異はありませんでした。
今回の検証からSQLを使用してETLを作成することは、まったく問題ない選択肢と言えそうです。
もちろん今回のケースに当てはまらない場合では、リネージュであったり取得できるメタデータに差異は出てくるかもしれませんが、必要十分なメタデータを取得可能であることがわかったのが今回の収穫です。
以上、どなたかのご参考になれば幸いです。







